从零打造私人AI知识库:Ollama + AnythingLLM 完全指南
在这个信息爆炸的时代,如何高效管理和利用自己的知识资产?本文将手把手教你搭建一个完全本地化、保护隐私的AI知识库系统。
🎯 为什么需要私人AI知识库?
想象这样的场景:
- 📚 你有大量的学习资料、工作文档,需要时却找不到
- 🔍 想快速了解一份长达100页的报告核心内容
- 💼 公司文档敏感,不能上传到ChatGPT等在线服务
- 🧠 希望AI成为你的"第二大脑",随时调取知识
解决方案就是:Ollama + AnythingLLM
核心优势
✅ 完全本地化 - 数据不出本地,保护隐私
✅ 免费开源 - 无需订阅费用,永久免费使用
✅ 离线运行 - 不依赖网络,随时可用
✅ 灵活定制 - 可选择不同模型,满足各种需求
📋 准备工作
系统要求
最低配置:
- CPU: 4核心以上
- 内存: 8GB(推荐16GB)
- 硬盘: 20GB可用空间
- 操作系统: Windows 10/11、macOS、Linux
推荐配置:
- CPU: 8核心以上
- 内存: 16GB以上
- 显卡: 支持CUDA的NVIDIA显卡(可选,能大幅提升速度)
需要下载的软件
- Ollama - 本地大语言模型运行环境
- AnythingLLM - 知识库管理界面
🚀 第一步:安装 Ollama
1.1 下载安装
访问 Ollama 官网:https://ollama.ai
根据你的操作系统选择对应版本:
Windows 用户:
# 下载 OllamaSetup.exe 后直接运行安装
# 安装过程约需 1-2 分钟
macOS 用户:
# 下载 Ollama-darwin.zip
# 解压后拖入应用程序文件夹
Linux 用户:
curl -fsSL https://ollama.ai/install.sh | sh
1.2 验证安装
打开终端(Windows 用户打开命令提示符或 PowerShell),输入:
ollama --version
如果显示版本号,说明安装成功!
1.3 下载 AI 模型
如果您不想使用命令行、则可以直接使用图形界面操作、代替命令行,请点击
这是关键步骤!我们需要下载一个大语言模型。推荐以下几个:
中文友好模型(推荐):
# Qwen3 4B - 阿里出品,中文优秀,推荐首选
ollama pull qwen3:4b
# Qwen3 8B - 更强大,需要更多内存(16GB+)
ollama pull qwen3:8b
英文模型:
# Llama 3.1 8B - Meta出品,综合性能好
ollama pull llama3.1:8b
# Mistral 7B - 轻量高效
ollama pull mistral:7b
代码专用模型:
# CodeLlama - 代码理解和生成
ollama pull codellama:7b
💡 提示:首次下载模型需要几分钟到十几分钟,取决于网速。7B 模型约 4GB,14B 模型约 8GB。
1.4 测试模型
下载完成后,测试一下:
ollama run qwen3:4b
进入对话界面后,输入:
你好,请介绍一下你自己
看到 AI 回复,说明模型运行正常!输入 /bye 退出。
1.5 常用 Ollama 命令
# 查看已安装的模型
ollama list
# 删除模型
ollama rm qwen3:8b
# 运行模型
ollama run qwen3:8b
# 查看模型信息
ollama show qwen3:8b
1.6 图形界面
Ollama 提供了图形界面,方便用户管理模型和运行对话。
开始前做一件重要的事情:设置您的模型存储位置
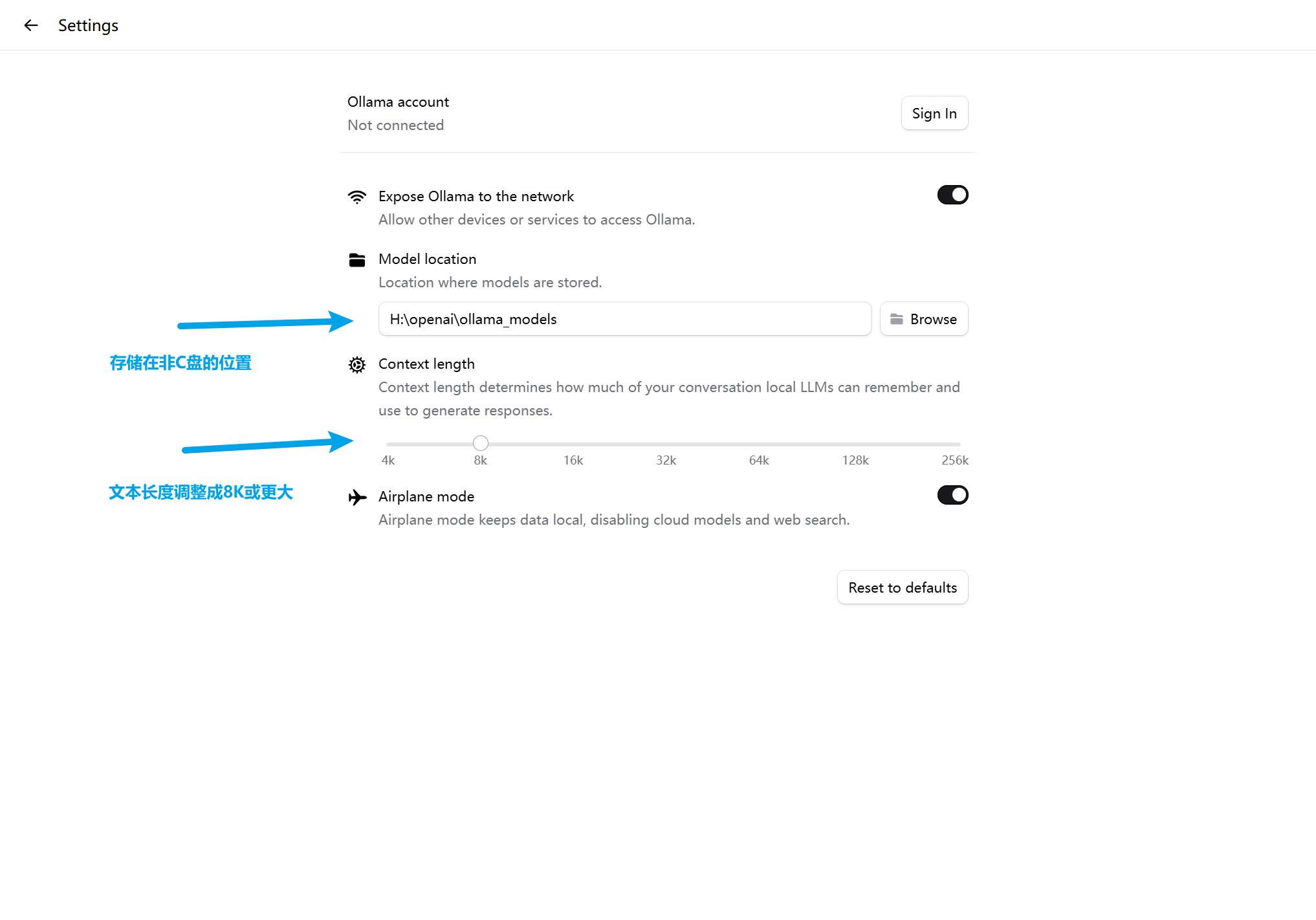
打开UI界面:
- 选择您要使用的模型,如 qwen3:4b, bge-m3 模型下载(这里先下载这两个模型、后续做私人知识库有用)
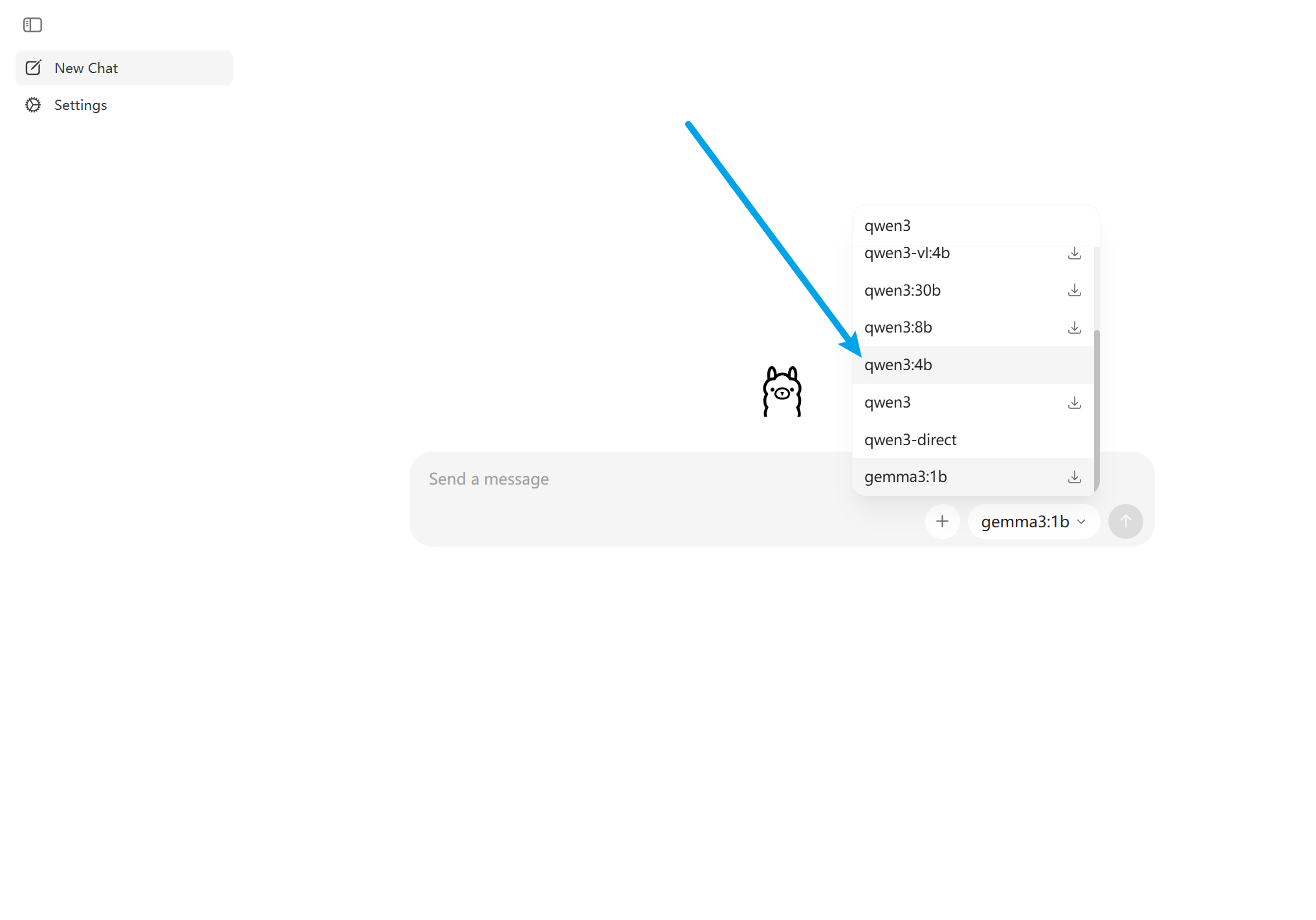
- 开始对话、系统会自动下载模型
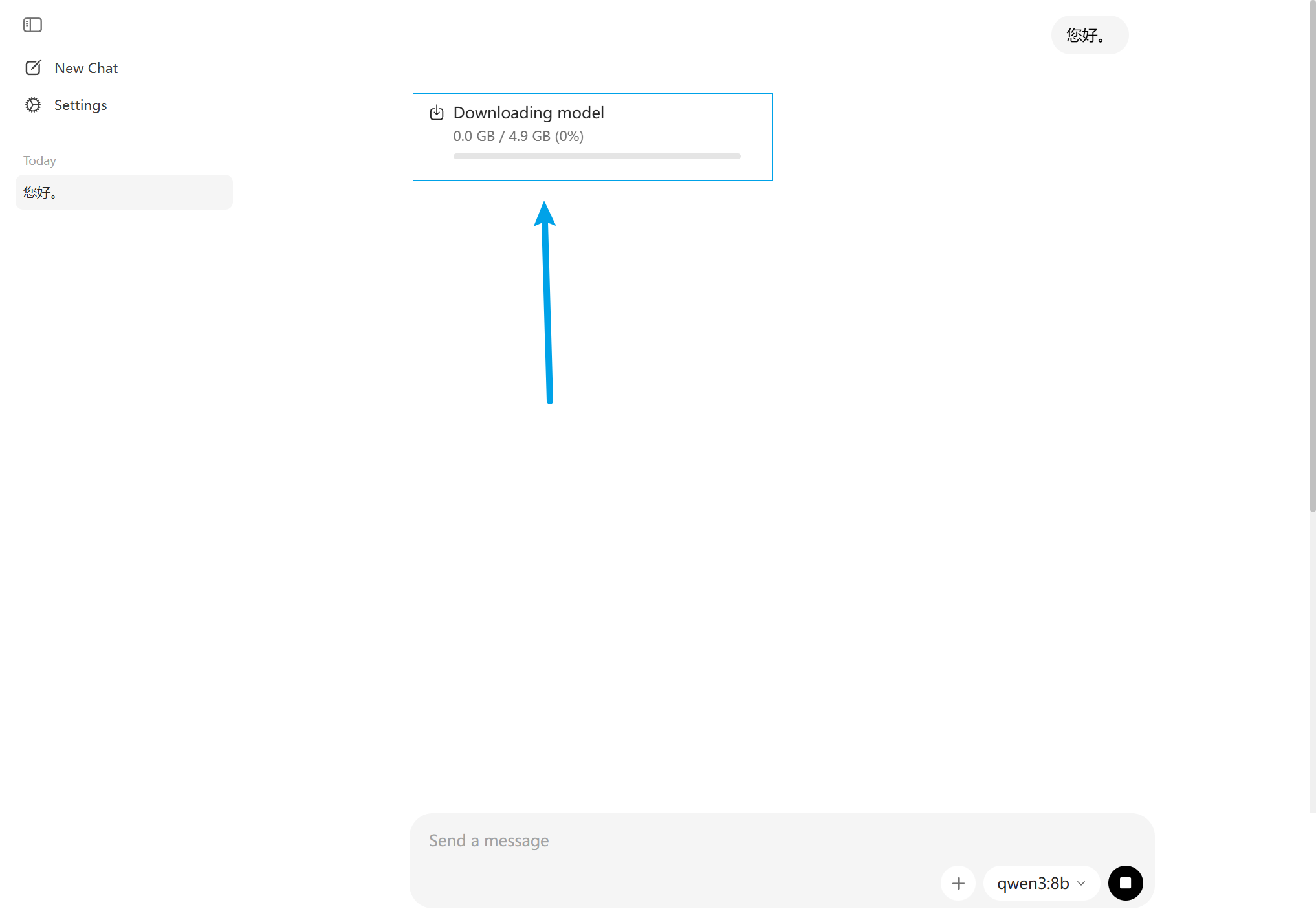
- 模型下载完后、会自动运行并回答您的问题
💻 第二步:安装 AnythingLLM
2.1 下载安装
截止2026年1月,桌面版本:v1.9.1
访问 AnythingLLM 官网:https://anythingllm.com
点击 Download 按钮,选择你的系统:

Windows:
- 下载
.exe安装文件 - 双击运行,按提示安装
macOS:
- 下载
.dmg文件 - 打开后拖拽到应用程序文件夹
Linux:
- 下载
.AppImage文件 - 添加执行权限后运行
安装时需要注意:
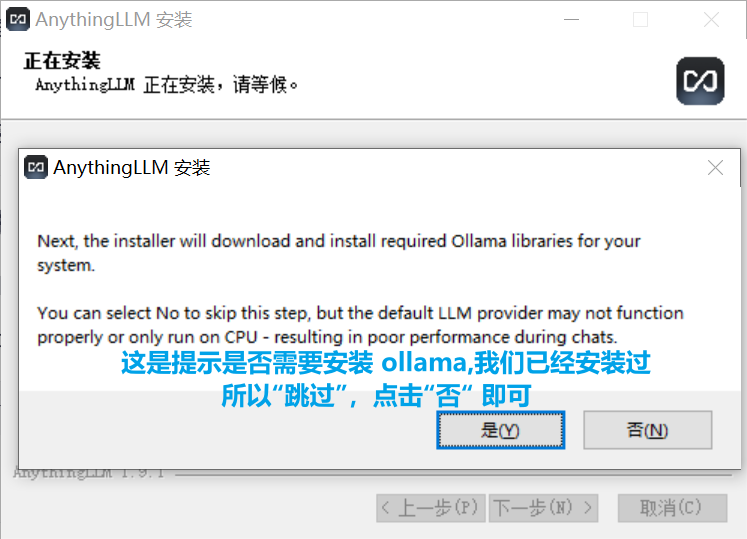
2.2 首次启动
打开 AnythingLLM,你会看到欢迎界面。
⚙️ 第三步:配置连接
3.1 配置语言模型(LLM)
这是最重要的配置步骤!
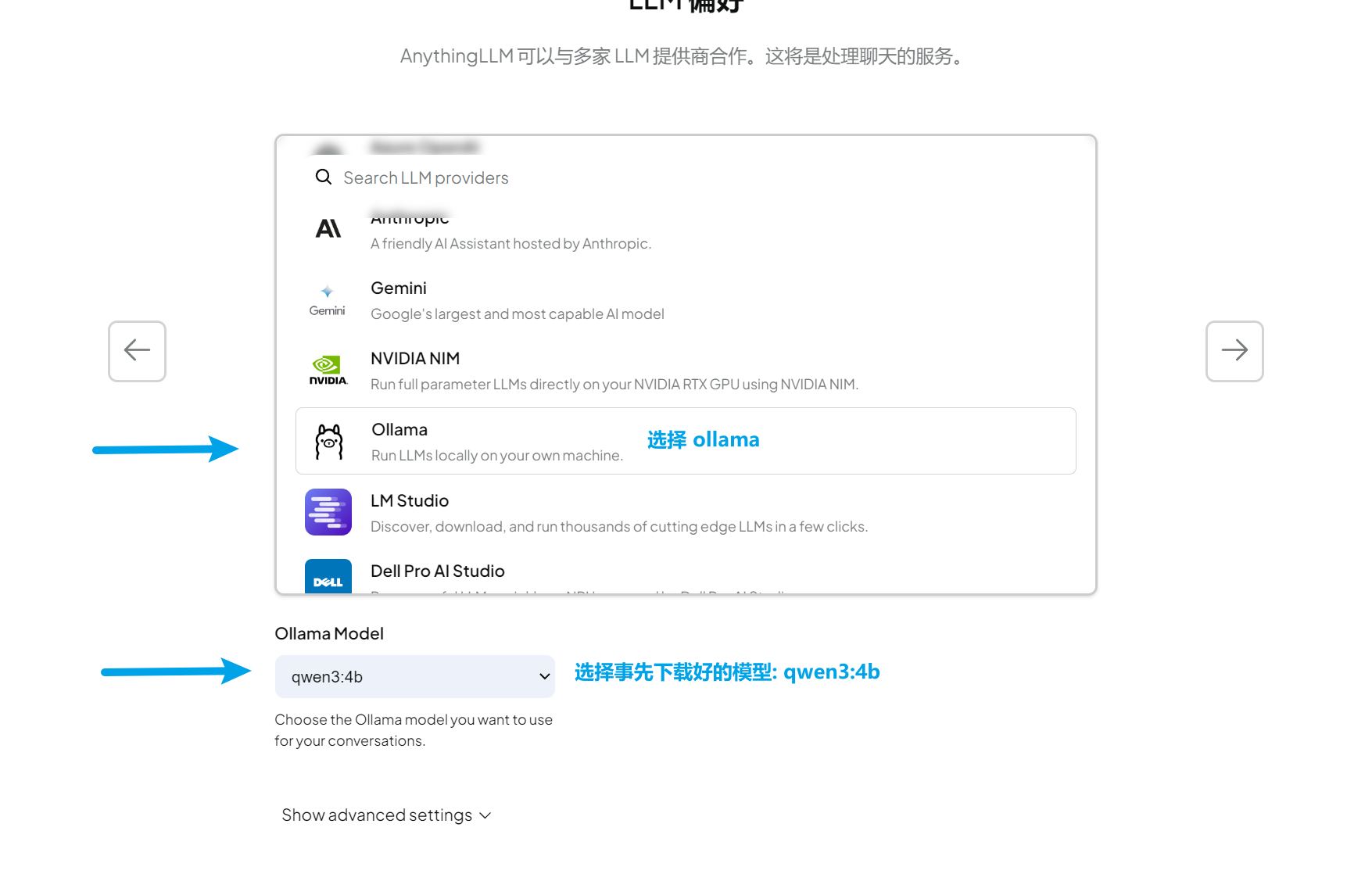
💡 说明:
http://localhost:11434是 Ollama 的默认运行地址,除非你修改过配置,否则不需要改动。
- 点击 “Save”(保存)
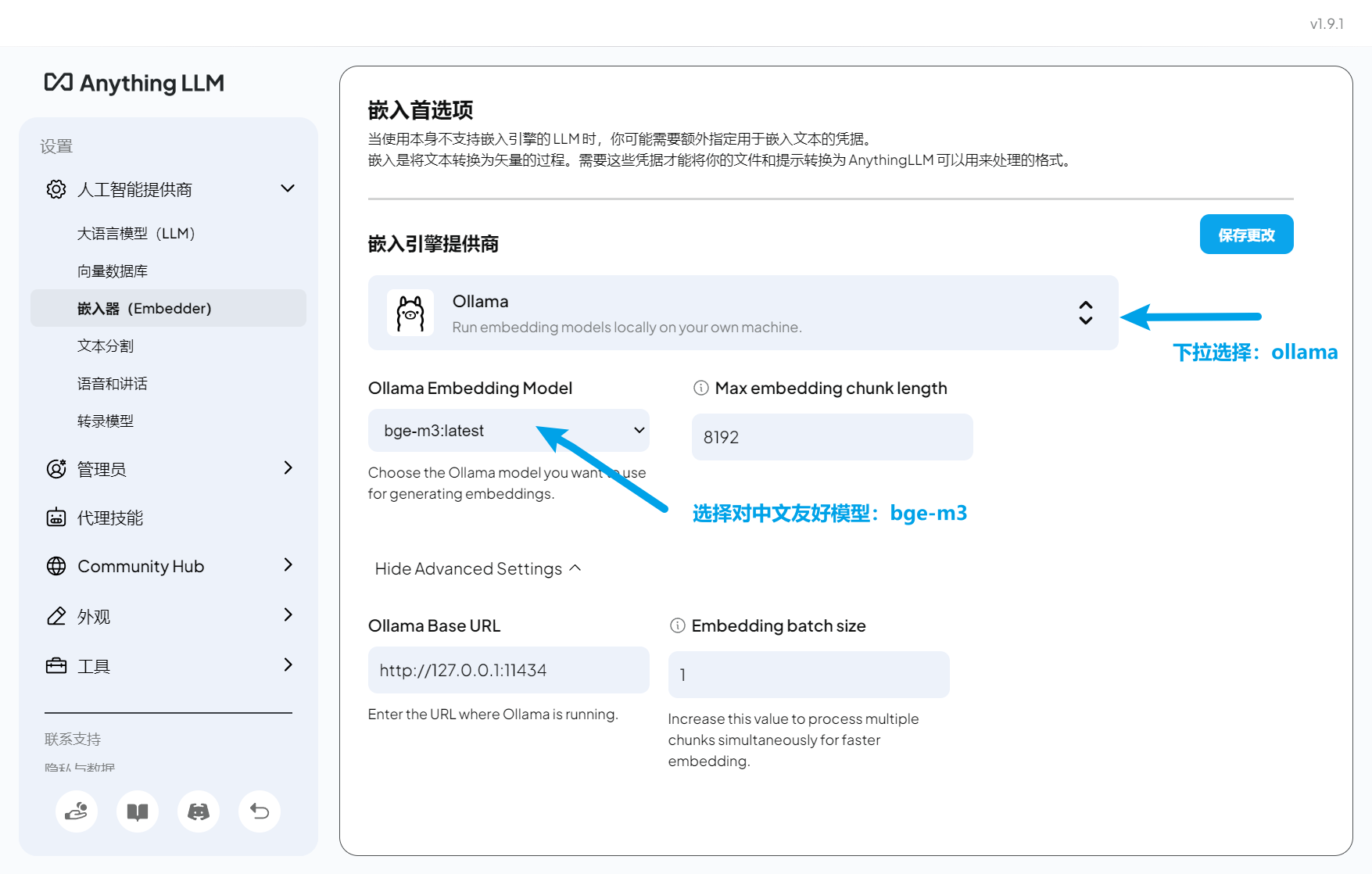
3.2 配置嵌入模型(Embedding)
嵌入模型用于将文档转换为向量,是知识库检索的核心。
- 在设置中选择 “Embedding Preference”(嵌入偏好)
- 选择 “Ollama”
- 模型选择:
bge-m3
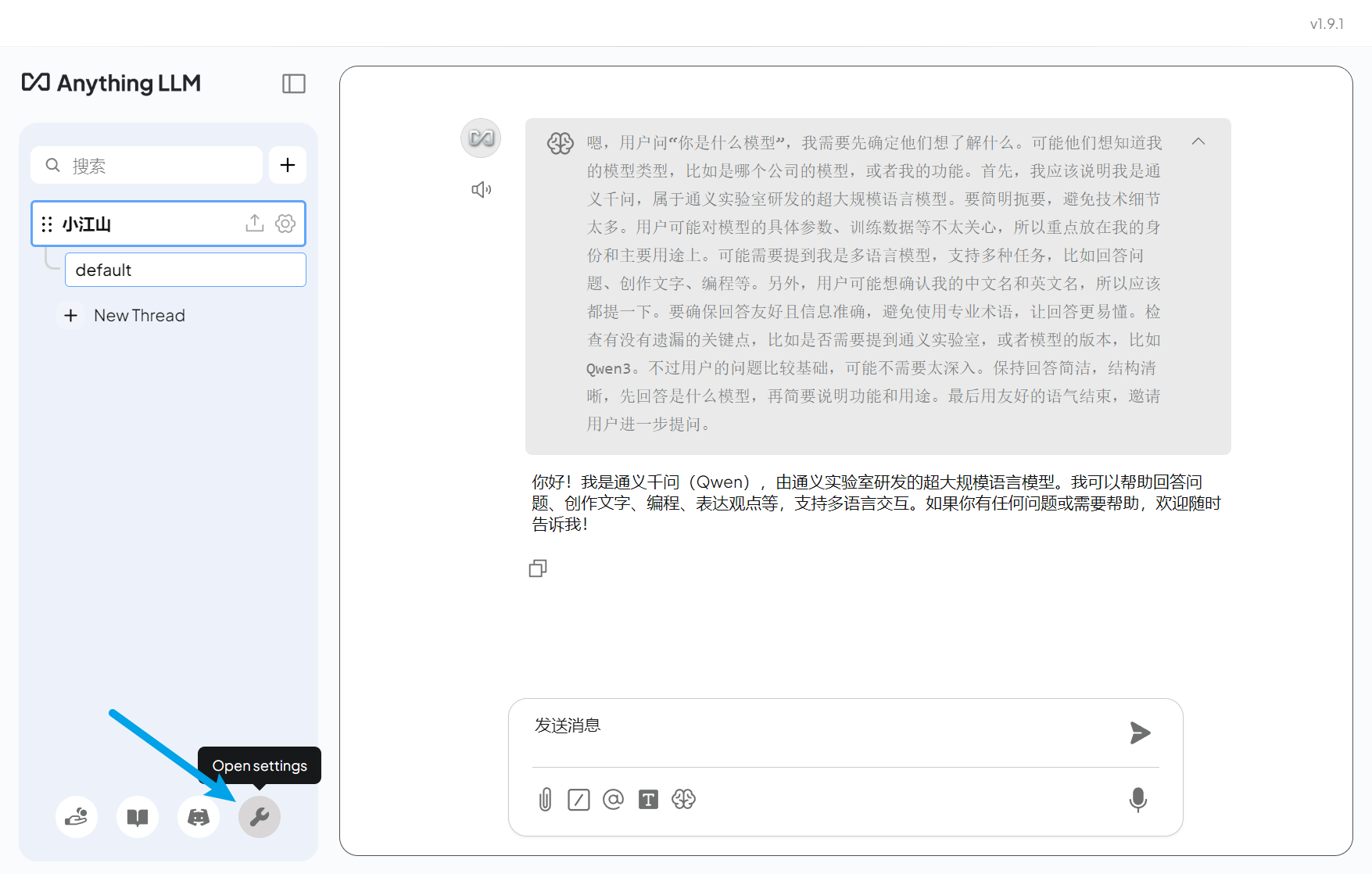
- 基本设置
3.3 测试连接
配置完成后,在设置页面底部通常有测试按钮,输入一个问题测试:
你好,请做个简单的自我介绍
如果收到正常回复,恭喜,配置成功!🎉
📚 第四步:创建第一个知识库
4.1 创建工作空间
- 点击 “New Workspace”(新建工作空间)
- 输入名称,例如:
- 技术文档库
- 学习资料库
- 公司项目文档
- 个人笔记库
- 选择图标和颜色(可选)
- 点击创建
💡 提示:你可以创建多个工作空间,将不同类型的文档分类管理。
4.2 准备文档
AnythingLLM 支持以下格式:
- 📄 PDF - 电子书、报告、论文
- 📝 Word - .docx、.doc 文档
- 📋 文本 - .txt、.md(Markdown)
- 🌐 网页 - 直接输入 URL 抓取内容
示例文档准备:
示例1: Python学习指南.pdf
示例2: 公司产品手册.docx
示例3: 项目需求文档.txt
示例4: 技术博客文章.md
4.3 上传文档
- 在工作空间界面,点击 “Upload Document” 📤
- 选择文件或直接拖拽到界面
- 等待文档上传和解析
批量上传: 可以一次选择多个文件,系统会依次处理。
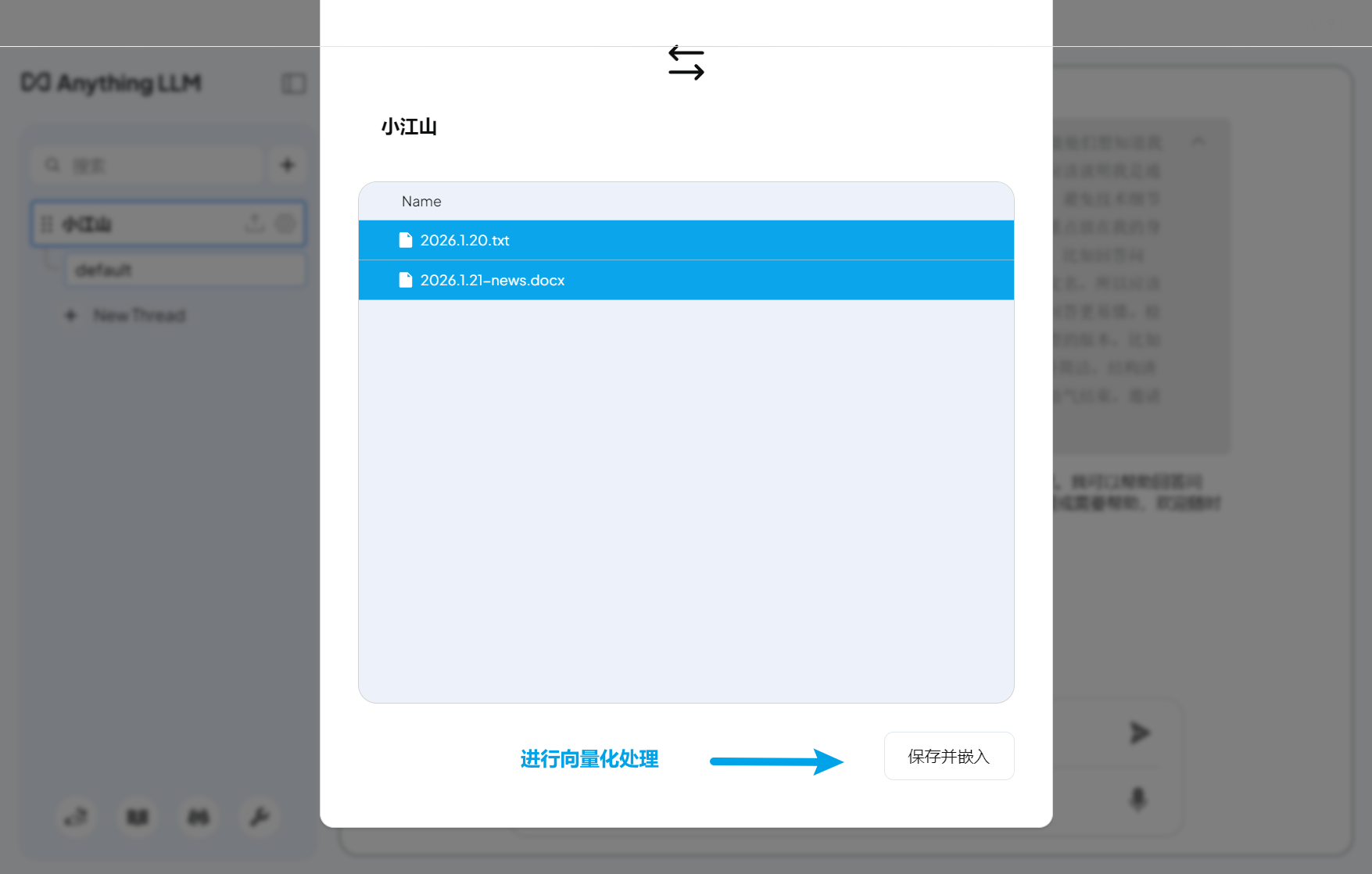
4.4 文档向量化
这是关键步骤:将文档转换为 AI 可理解的向量。
- 上传完成后,在文档列表中选择要添加的文档
- 点击 “Move to Workspace”(移动到工作空间)
- 等待向量化处理完成
处理时间取决于:
- 文档大小
- 电脑性能
- 文档数量
通常几秒到几分钟不等。
4.5 查看文档
在工作空间中,你可以:
- 📋 查看所有已添加的文档
- 🗑️ 删除不需要的文档
- ➕ 随时添加新文档
- 👁️ 预览文档内容
💬 第五步:开始智能问答
现在,最激动人心的时刻到了!
5.1 基础问答
在聊天框中输入问题,AI 会基于你的知识库回答。
示例问题:
Q: Python中如何定义函数?
A: [AI会从你上传的Python文档中提取相关内容回答]
Q: 我们公司的主打产品是什么?
A: [AI会从产品手册中找到答案]
5.2 文档总结
让 AI 总结长文档:
Q: 总结一下"项目需求文档"的核心内容
Q: 这份报告的主要结论是什么?
Q: 列出文档中提到的所有关键步骤
5.3 对比分析
跨文档查询和对比:
Q: 对比文档A和文档B中关于XX的描述
Q: 这两份报告的观点有什么不同?
Q: 总结所有文档中关于"最佳实践"的建议
5.4 深度提问
Q: 基于上传的文档,给我制定一个学习计划
Q: 分析一下文档中可能存在的问题或风险
Q: 如果要实现文档中描述的功能,需要哪些步骤?
5.5 查看引用来源
AnythingLLM 的强大之处在于:
每个回答都会标注信息来源,包括:
- 📄 来自哪个文档
- 📍 文档的哪个部分
- 📝 原始文本片段
这样你可以:
- ✅ 验证答案的准确性
- 📖 追溯到原文阅读
- 🔍 了解信息的上下文
🎓 实战案例演示
案例1:技术学习助手
场景:学习 Python 编程
上传文档:
- Python官方教程.pdf
- 数据结构与算法.pdf
- 编程实战练习.md
实战问答:
Q: Python中列表和元组的区别是什么?
A: [AI综合多个文档给出详细对比]
Q: 如何实现一个二叉树?给我完整代码
A: [AI提供代码示例并解释]
Q: 总结所有关于性能优化的建议
A: [AI从多份文档中提取要点]
案例2:企业知识管理
场景:公司新员工培训
上传文档:
- 公司简介.pptx
- 产品手册.pdf
- 规章制度.docx
- 常见问题FAQ.txt
实战问答:
Q: 公司的核心业务是什么?
A: [快速了解公司定位]
Q: 请假流程是怎样的?
A: [查询规章制度]
Q: 客户最常问的问题有哪些?
A: [提取FAQ重点]
案例3:研究论文助手
场景:学术研究
上传文档:
- 相关领域论文10篇.pdf
- 研究方法综述.pdf
- 实验数据报告.xlsx
实战问答:
Q: 总结近期研究的主要趋势
A: [综合分析多篇论文]
Q: 有哪些常用的研究方法?
A: [提取方法论内容]
Q: 这些研究的局限性是什么?
A: [批判性分析]
案例4:个人笔记系统
场景:打造"第二大脑"
上传文档:
- 读书笔记合集
- 学习心得
- 灵感记录
- 项目经验总结
实战问答:
Q: 我之前读过关于时间管理的书,主要观点是什么?
A: [快速回顾笔记]
Q: 整理一下我在XX项目中的经验教训
A: [知识萃取]
Q: 基于我的笔记,给我一些建议
A: [个性化建议]
🔧 进阶技巧
技巧1:优化提问方式
❌ 模糊提问:
告诉我关于产品的信息
✅ 具体提问:
产品手册中提到的三大核心功能分别是什么?每个功能的主要应用场景是什么?
技巧2:分类管理工作空间
建议创建多个专用工作空间:
📁 工作空间结构:
├── 工作文档
│ ├── 项目资料
│ ├── 会议记录
│ └── 规章制度
├── 学习资料
│ ├── 技术书籍
│ ├── 在线课程笔记
│ └── 博客文章
├── 个人笔记
│ ├── 读书笔记
│ ├── 灵感记录
│ └── 日记
└── 客户资料
├── 产品文档
├── FAQ
└── 案例研究
技巧3:文档预处理
为了获得更好的效果:
文档格式:
- ✅ 使用清晰的标题和段落结构
- ✅ 保持文字清晰,避免图片中的文字(OCR识别可能不准)
- ✅ 大文件建议分章节上传
内容质量:
- ✅ 确保文档内容准确
- ✅ 移除无关的广告、页眉页脚
- ✅ 统一文档的语言和格式
技巧4:使用不同模型
根据任务选择合适的模型:
中文任务:
ollama pull qwen3:14b # 中文理解更好
代码相关:
ollama pull codellama:13b # 代码生成优化
快速响应:
ollama pull qwen3:8b # 速度快,资源占用少
切换模型: 在 AnythingLLM 设置中可以随时更换模型。
技巧5:自定义系统提示词
在工作空间设置中,可以自定义系统提示词:
示例1 - 技术助手:
你是一个专业的技术顾问,擅长解释复杂的技术概念。
请用简洁清晰的语言回答问题,必要时提供代码示例。
示例2 - 学习助手:
你是一个耐心的学习导师,善于用浅显易懂的方式讲解知识点。
回答时请:1) 先给出核心概念 2) 举例说明 3) 提供练习建议
示例3 - 商务助手:
你是一个专业的商务顾问,精通企业管理和市场分析。
回答要点:准确、专业、有数据支撑、提供可行建议。
技巧6:定期维护知识库
每周维护:
- 📥 添加新产生的文档
- 🗑️ 清理过时的内容
- 🔄 更新变化的资料
每月检查:
- 📊 评估知识库使用效果
- 🎯 调整工作空间分类
- 🔧 优化提示词和设置
❓ 常见问题解答
Q1: Ollama 启动失败怎么办?
可能原因:
- 端口 11434 被占用
- 防火墙拦截
- 安装不完整
解决方法:
# Windows: 检查端口占用
netstat -ano | findstr "11434"
# 杀死占用进程或更换端口
# 在 Ollama 配置中指定新端口
Q2: 模型下载很慢怎么办?
方法1:使用镜像源
# 设置环境变量使用国内镜像
# Linux/Mac:
export OLLAMA_HOST=https://ollama-mirror.example.com
# Windows: 在系统环境变量中设置
方法2:手动下载
- 从其他渠道下载模型文件
- 放入 Ollama 模型目录
Q3: AI 回答不准确怎么办?
改进方法:
优化文档质量
- 确保文档内容准确完整
- 移除无关内容
改进提问方式
- 提供更多上下文
- 问题更具体明确
调整模型
- 尝试更大的模型(14B、30B)
- 使用专门领域的模型
Q4: 内存不够怎么办?
优化建议:
- 使用更小的模型
# 使用 0.6B 而不是 4B,8b
ollama pull qwen3:0.6b
一次处理更少文档
- 分批上传文档
- 创建多个小型工作空间
关闭其他应用
- 运行 Ollama 时关闭大型应用
- 释放内存空间
Q5: 可以同时使用多个模型吗?
可以!
# 下载多个模型
ollama pull qwen3:8b
ollama pull llama3.1:8b
ollama pull codellama:7b
# 在不同工作空间使用不同模型
# 在 AnythingLLM 的工作空间设置中切换
Q6: 如何备份我的知识库?
备份位置:
AnythingLLM 的数据通常存储在:
- Windows:
C:\Users\<用户名>\.anythingllm - macOS:
~/Library/Application Support/anythingllm - Linux:
~/.anythingllm
备份方法:
# 直接复制整个文件夹到安全位置
# 建议定期备份
Q7: 能处理多大的文档?
理论上无限制,但实际受限于:
- 电脑内存
- 处理时间
- 模型上下文长度
建议:
- 单个文档不超过 50MB
- 超大文档建议分割
- 总文档量根据内存调整(建议不超过 1000 个)
🎯 使用场景推荐
场景1:学生/研究者
📚 用途:管理学习资料、论文笔记
💡 优势:快速检索知识点、跨文档总结
🎓 适合:备考、写论文、做研究
场景2:程序员
💻 用途:技术文档库、代码片段管理
💡 优势:查询API、学习框架、解决bug
🔧 适合:日常开发、学习新技术
场景3:企业员工
📊 用途:公司文档、项目资料管理
💡 优势:快速查询制度、了解项目历史
🏢 适合:新人培训、跨部门协作
场景4:内容创作者
✍️ 用途:素材库、灵感记录
💡 优势:快速查找素材、生成创意
🎨 适合:写作、设计、视频制作
场景5:自由职业者
💼 用途:客户资料、项目文档
💡 优势:快速响应客户、管理多项目
🚀 适合:咨询、设计、开发等
🔐 隐私与安全
为什么选择本地部署?
数据隐私:
- ✅ 所有数据存储在本地
- ✅ 不上传到任何云端
- ✅ 完全掌控自己的数据
企业合规:
- ✅ 满足数据不出境要求
- ✅ 符合企业保密规定
- ✅ 避免数据泄露风险
成本控制:
- ✅ 无订阅费用
- ✅ 无API调用限制
- ✅ 一次部署,永久使用
安全建议
定期备份
- 每周备份知识库数据
- 使用加密存储
访问控制
- 设置电脑密码
- 工作空间分离敏感数据
更新维护
- 定期更新 Ollama 和 AnythingLLM
- 关注安全公告
🚀 性能优化
提升响应速度
1. 使用 GPU 加速(NVIDIA 显卡)
# Ollama 自动检测 GPU,无需额外配置
# 确保安装了最新的 NVIDIA 驱动
2. 选择合适的模型大小
7B 模型:快速,适合日常使用
14B 模型:平衡性能和质量
30B+ 模型:最佳质量,需要高配置
3. 优化文档数量
单个工作空间建议不超过 500 个文档
超过后考虑分类到不同工作空间
降低资源占用
1. 关闭不用的模型
# 列出所有模型
ollama list
# 删除不常用的模型
ollama rm model_name
2. 调整并发数
在 AnythingLLM 设置中调整:
- 减少同时处理的文档数
- 降低向量化并发数
📈 从入门到精通路径
第一周:熟悉基础
- ✅ 完成安装配置
- ✅ 创建第一个工作空间
- ✅ 上传 10-20 个文档
- ✅ 尝试各种提问方式
第二周:深入使用
- ✅ 创建 3-5 个分类工作空间
- ✅ 尝试不同的模型
- ✅ 学习优化提问技巧
- ✅ 总结使用心得
第三周:高级功能
- ✅ 自定义系统提示词
- ✅ 批量导入文档
- ✅ 跨工作空间查询
- ✅ 建立使用习惯
持续优化
- 🔄 定期更新内容
- 📊 评估使用效果
- 🎯 根据需求调整
- 🚀 探索新功能
🎉 总结
恭喜你!通过本教程,你已经掌握了:
✅ 搭建本地 AI 运行环境
✅ 创建和管理知识库
✅ 智能问答和文档分析
✅ 优化使用体验
核心优势回顾
🔒 隐私保护 - 数据完全本地化
💰 零成本 - 完全免费开源
🎯 高效率 - 快速检索和总结
🔧 可定制 - 灵活配置和扩展
下一步建议
- 立即行动 - 按教程搭建自己的知识库
- 持续优化 - 根据使用情况调整配置
- 分享经验 - 帮助更多人受益
- 探索进阶 - 学习 API 集成、自动化等
📚 相关资源
官方文档
- Ollama 官网: https://ollama.ai
- AnythingLLM 官网: https://anythingllm.com
- Ollama GitHub: https://github.com/ollama/ollama
- AnythingLLM GitHub: https://github.com/Mintplex-Labs/anything-llm
模型资源
- Hugging Face: https://huggingface.co
- Ollama 模型库: https://ollama.ai/library
社区支持
- Ollama Discord 社区
- AnythingLLM Discord 社区
- GitHub Issues 区
💬 反馈与交流
如果本教程对你有帮助,欢迎:
- ⭐ 点赞收藏
- 💬 评论交流
- 🔗 分享给朋友
- 📧 反馈问题和建议
祝你使用愉快,打造属于自己的智能知识库! 🎉