Filebeat 学习(一) 原理&安装
字数:
89
·
阅读:
1 分钟
·
访问:
-
Filebeat是用于转发和集中日志数据的轻量级传送程序。作为服务器上的代理安装,Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
架构
工作原理是启动 filebeat 时, 它将启动一个或多个输入, 这些输入将在日志数据指定位置中查找, 对于 filebeat 所找到的每个日志, filebeat 都会启动收集器, 每个收割机都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
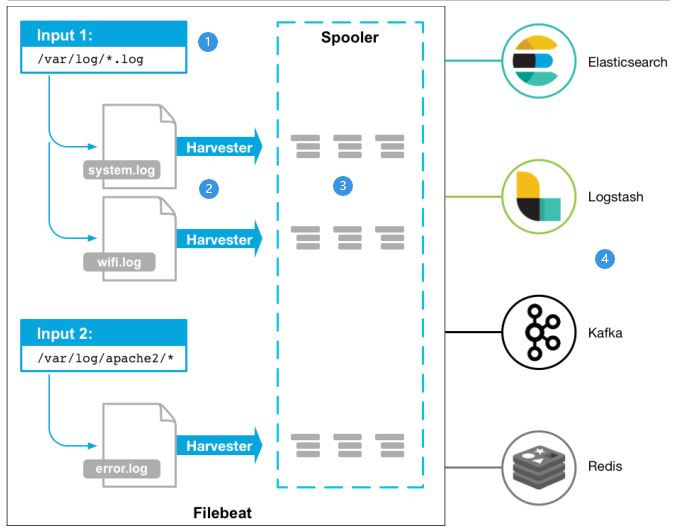
- 配置输入源, 可以是日志(log), 也可以是标准输入(stdin), 可以配置多个输入(input)
- 为每个日志启一个(Harvester) 收集器, 将不停的读取数据
- 数据卷轴, 将数据不断的输出到其它终端
- 终端, 如 es, kafaka, redis
原理
Filebeat由两个主要组件组成:prospector 和 harvester
harvester 收集器
负责读取单个文件的的内容,如果文件被删除啦,也会继续监听这个文件的变化.
prospector 探测器
prospector 负责管理 harvester 并找到所有要读取的文件来源
如果输入类型是日志类型, 则查找器路径匹配的所有文件, 并为每一个文件启动一个 harvester 收集器
filebeat 目前支持两种 prospector 类型: stdin 和 log
Filebeat 如何保持文件的读取状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
- 注册文件位于
/usr/local/filebeat/data/registry/filebeat/data.json
- 注册文件位于
- 该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
- 如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件
安装
官方下载 https://www.elastic.co/cn/downloads/beats/filebeat, 一般国内都很慢, 推荐使用国内镜像下载. https://mirrors.huaweicloud.com/filebeat/ 找到对应的版本.
我这里使用是 7.8.0 版本
cd /usr/local/src
wget https://mirrors.huaweicloud.com/filebeat/7.8.0/filebeat-7.8.0-linux-x86_64.tar.gz
解压到/usr/local
tar -zxvf filebeat-7.8.0-linux-x86_64.tar.gz -C /usr/local
如何继续玩,推荐下一篇 Filebeat 学习(二) 配置